dataMaid: Your personal assistant for cleaning up the data cleaning process
As data analysts, we all have tasks that we enjoy more than others. Some like the exploratory analysis steps, some like statistical computing, while others enjoy visualizing and communicating the results of their analyses. But we have yet to meet a data analyst that is passionate about data cleaning, even though everyone is very much aware of the importance of a thorough, well-documented data cleaning. This first step of virtually any data analysis process is often unavoidable and key for smooth sailing through the rest of the data analysis.
As everybody’s least favorite child, data cleaning often suffers the burden of neglect and sloppyness. But there is another way. There’s the dataMaid way. dataMaid is an R-package created by impatient data analysts for impatient data analysts that want to get on with their data analyses already. dataMaid adds to the growing suite of useful pre-analysis-oriented R packages, that have recently submerged on CRAN, including janitor (for data import); plyr, data.table and DataCombine (for data wrangling); validate (for checking internal validity within a dataset), among others. dataMaid can be viewed as one of the first steps as it helps the investigators to identify potential problems in the datasets since the variables in the dataset can only be understood in the proper context of their origin. This often requires a collaborative effort between an expert in the field and a statistician or data scientist, which may be why the process of proper data cleaning is not always undertaken. In many situations, these errors are discovered in the process of the data analysis (e.g., a categorical variable with numeric labels for each category may be wrongly classified as a quantitative variable or a variable where all values have erroneously been coded to the same value), but in other cases a human with knowledge about the data context area is needed to identify possible mistakes in the data (e.g., if there are 4 categories for a variable that should only have 3). The major advantage of dataMaid is that all checks undertaken are precisely specified so it is documented what types of error that were sought after.
The code presented below were produced by using the latest development version of dataMaid available on Github (0.9.7) but similar results can be obtained by using the package version avaiable on CRAN.
Creating data overview reports
By now, you might expect dataMaid to be a virtual robot ready for doing all your dirty work. You might even worry about the early coming of the robot overtake, which might then again make you slightly iffy about this whole dataMaid idea. But fear not. We have not (yet) succeeded in creating artificial intelligence for data cleaning. Therefore, human decision making is still very much needed. What dataMaid does do is to make the basis of these decisions well-documented, easy to read and easy to share - even with colleagues that are not fluent in R.
The main capability of dataMaid is autogenerating data overview documents that summarize each variable in a dataset and flags typical problems, depending on the data type of the variable. Let us consider an example dataset that is part of the dataMaid package
suppressPackageStartupMessages(library("dataMaid")) # Load package
data(toyData) # Get data
toyData # Show data## # A tibble: 15 x 6
## pill events region change id spotifysong
## <fct> <dbl> <fct> <dbl> <fct> <fct>
## 1 red 1 "a" -0.626 1 Irrelevant
## 2 red 1 "a" 0.184 2 Irrelevant
## 3 red 1 "a" -0.836 3 Irrelevant
## 4 red 2 "a" 1.60 4 Irrelevant
## 5 red 2 "a" 0.330 5 Irrelevant
## 6 red 6 "b" -0.820 6 Irrelevant
## 7 red 6 "b" 0.487 7 Irrelevant
## 8 red 6 "b" 0.738 8 Irrelevant
## 9 red 999 "c" 0.576 9 Irrelevant
## 10 red NA "c" -0.305 10 Irrelevant
## 11 blue 4 "c" 1.51 11 Irrelevant
## 12 blue 82 "." 0.390 12 Irrelevant
## 13 blue NA " " -0.621 13 Irrelevant
## 14 <NA> NaN "other" -2.21 14 Irrelevant
## 15 <NA> 5 "OTHER" 1.12 15 IrrelevantThe toyData data frame contains 6 variables and if we want assist the investigators in indentifying possible errors in the dataset then we call the makeDataReport() function, which is the main function of the dataMaid package:
makeDataReport(toyData) # Produce data reportThis produces and opens a pdf report in which an overview of the dataset is given, and each variable is presented in turn and submitted to various checks for typical problems. The overview is a simple summary and the results from the data cleaning process and looks like this

The main part of the document provides the reader information about each variable and it looks like this
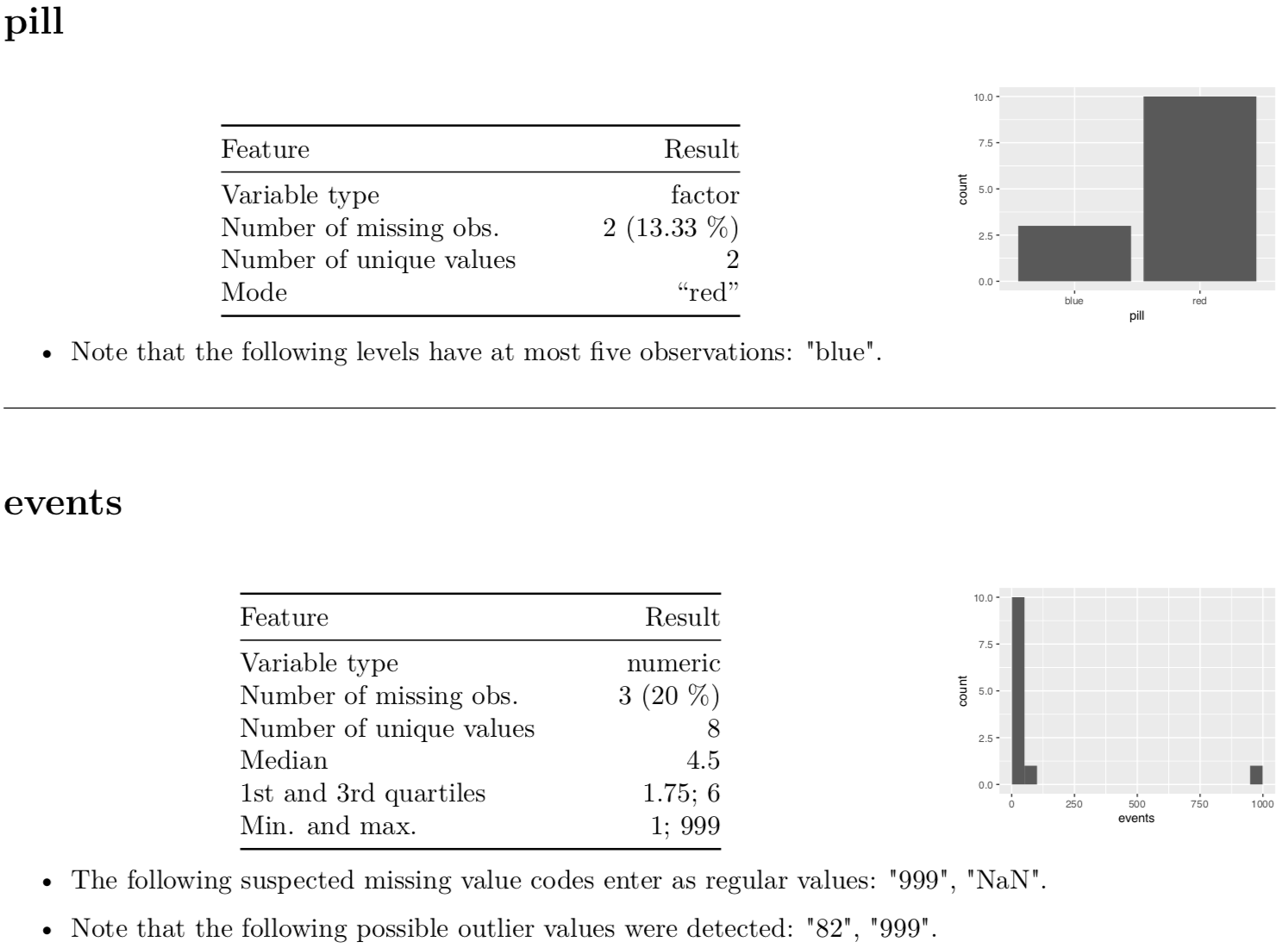
The report also includes an overview of what checks are performed for each variable and the default options are presented here:

The output report is intended as a guide for identifying potential errors and as a blueprint for discussion between the data analyst and the field experts, and since the report is readable by data analysts and field experts alike, it contributes to an inter-field dialogue about the data at hand. Oftentimes, e.g., distinguishing between faulty codings of a numeric value and unusual, but correct, values requires problem-specific expertise that might not be held by the data analyst. Hopefully, having easy access to data descriptions through dataMaid will help this sharing of knowledge.
Tweaking the cleaning
The choice of checks can be controlled in the arguments of makeDataReport() and user-defined checks can also be added for customized data cleaning needs. For more on this, we refer to the GitHub page and the manuscript found there. Note that makeDataReport() also allows for e.g. building html-documents rather than pdfs (using the argument output = "html"), only including variables flagged as problematic in the report (onlyProblematic = TRUE), not including e.g. figures (mode = c("summarize", "check")) among many other options, so all in all, a lot of personal preferences can be accomodated through simple makeDataReport() calls.
Using dataMaid interactively
We have found the data overview report to be a very convenient tool for documenting the data cleaning process and for discussing problems in the data with collaborators. But sometimes it is also nice to be able to work interactively in the R-console. The interactive functionality of dataMaid is centered around three steps of data assesment:
- Summarize: What is in the variable?
- Visualize: What does the distribution look like?
- Check: What potential problems do we find in the variable?
Each of these three steps have a dedicated function, named summarize(), visualize() and check(), respectively, that can be called on datasets as well as singular variables:
summarize(toyData[, c("pill", "events")]) #summarize a subset of a dataset## $pill
## $pill$variableType
## Variable type: factor
## $pill$countMissing
## Number of missing obs.: 2 (13.33 %)
## $pill$uniqueValues
## Number of unique values: 2
## $pill$centralValue
## Mode: "red"
## $pill$refCat
## Reference category: blue
##
## $events
## $events$variableType
## Variable type: numeric
## $events$countMissing
## Number of missing obs.: 3 (20 %)
## $events$uniqueValues
## Number of unique values: 8
## $events$centralValue
## Median: 4.5
## $events$quartiles
## 1st and 3rd quartiles: 1.75; 6
## $events$minMax
## Min. and max.: 1; 999summarize() shows the output that is put into each variable overview, and contains information about features that depend on the variable type. It is possible to modify the summarize() function and/or to provide you own custom information to summarize() (for more details on writing your own custom summarize() function see the documentation at the GitHub page).
check() runs through the variable-type-dependent checks
check(toyData$events) #check a single variable## $identifyMissing
## The following suspected missing value codes enter as regular values: 999, NaN.
## $identifyOutliers
## Note that the following possible outlier values were detected: 82, 999.For a numeric variable, two default checks are run: are there any elements that could be potential miscodings of NA (in this case 999 and NaN are flagged as possible errors), and possible outliers are identified. 82 and 999 are sufficiently far away from the other observations to be flagged as potential outliers, so the check draws the attention to those values.
Visualizations are done with the visualize() function and they provide a graphical overview of the distribution of the data. Factors are shown as bar plots while numeric variables are shown as histograms.
visualize(toyData) #visualize a dataset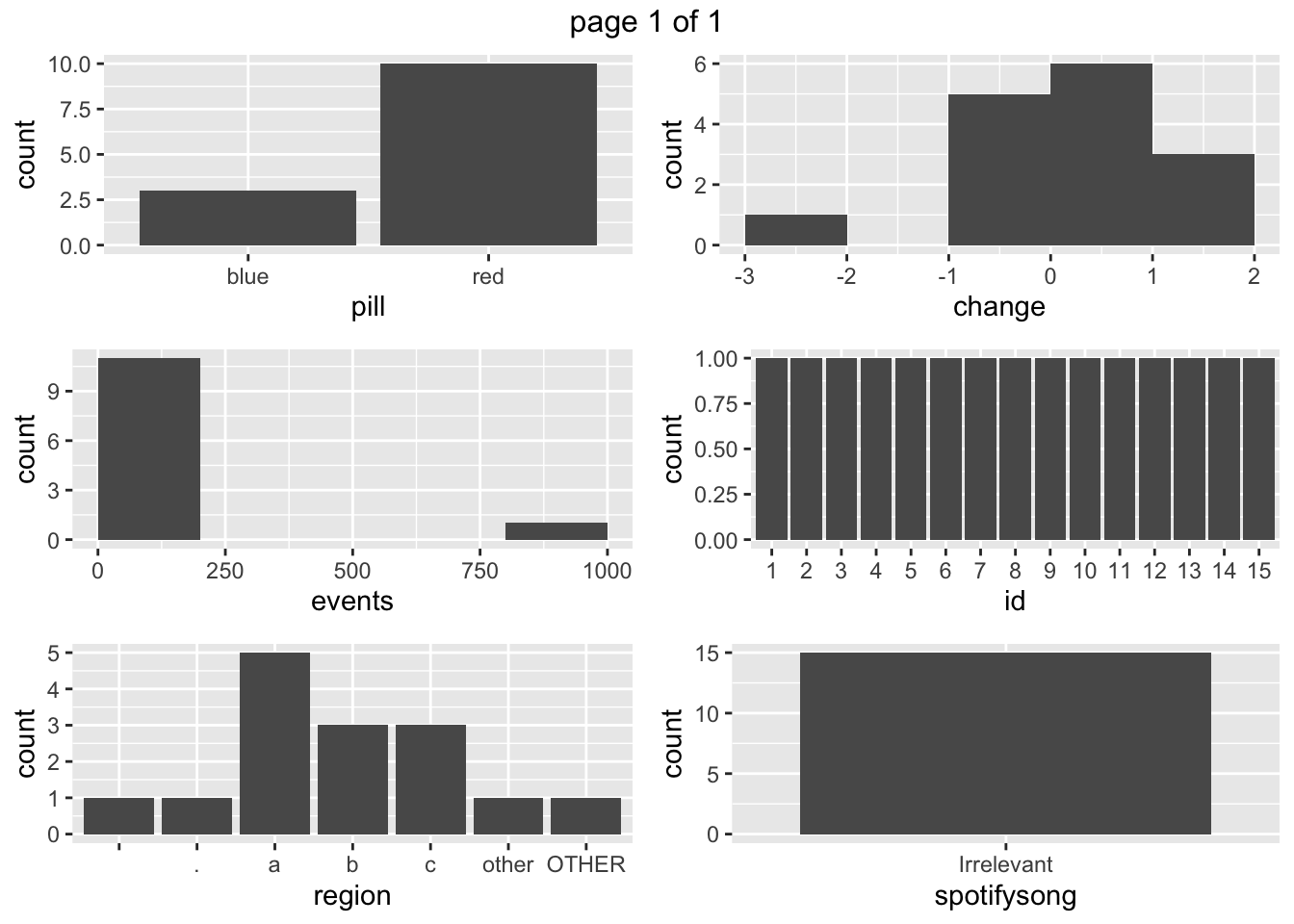
Figur 1: The result of calling visualize() on the full toyData dataset
One can also apply a single, specific summary- or check-function to a variable. All available summary-, visual- or check-functions can be seen by calling allXXXFunctions() where XXX is either summary, visual or check. For instance, we find all available checks by typing:
allCheckFunctions()----------------------------------------------------------------------------------------
name description classes
------------------------- -------------------------------- -----------------------------
identifyCaseIssues Identify case issues character, factor
identifyLoners Identify levels with < 6 obs. character, factor
identifyMissing Identify miscoded missing character, factor, integer,
values labelled, logical, numeric
identifyNums Identify misclassified numeric character, factor, labelled
or integer variables
identifyOutliers Identify outliers Date, integer, numeric
identifyOutliersTBStyle Identify outliers (Turkish Date, integer, numeric
Boxplot style)
identifyWhitespace Identify prefixed and suffixed character, factor, labelled
whitespace
isCPR Identify Danish CPR numbers character, Date, factor,
integer, labelled, logical,
numeric
isEmpty Check if the variable contains character, Date, factor,
only a single value integer, labelled, logical,
numeric
isKey Check if the variable is a key character, Date, factor,
integer, labelled, logical,
numeric
isSupported Check if the variable class is character, Date, factor,
supported by dataMaid. integer, labelled, logical,
numeric
----------------------------------------------------------------------------------------Then, we can identify values in a variable that look like miscoded missing values by calling
identifyMissing(toyData$events)## The following suspected missing value codes enter as regular values: 999, NaN.Note that the problematic values found by this function can be extracted, as all check functions return checkResult objects, that are really just named lists:
missVar2 <- identifyMissing(toyData$events)
str(missVar2)## List of 3
## $ problem : logi TRUE
## $ message : chr "The following suspected missing value codes enter as regular values: \\\"999\\\", \\\"NaN\\\"."
## $ problemValues: num [1:2] 999 NaN
## - attr(*, "class")= chr "checkResult"This implies that the miscoded missing value problem can be solved by writing e.g.
toyData$events[toyData$events %in% missVar2$problemValues] <- NAthereby replacing the 999 and NaN values in the var2 variable with NA values.
Digging deeper and getting your hands dirty
dataMaid is designed to be fully flexible and extendable such that the user can write functions to enhance the cleaning process. If you want to dig deeper on how to customize your data cleaning process then visit the documentation on the GitHub page which provides examples of creating your own check(), summarize(), and visualize() functions.