Tips til læse og afkode statistikken i videnskabelige artikler
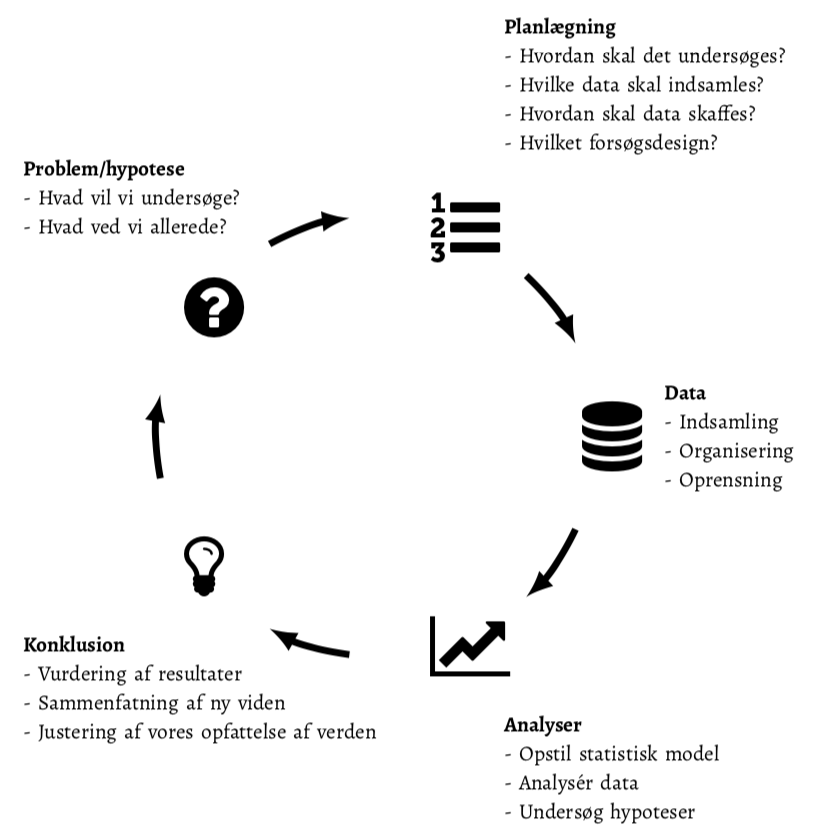
Forskere kommunikerer deres forskningsresultater gennem videnskabelige artikler, og derfor er det nødvendigt at kunne læse og forstå disse for at kunne vurdere, diskutere og forstå de nyeste forskningsresultater. Mange videnskabelige artikler er bygget over samme skelet, og når man kender denne opbygning er det lettere at danne sig et overblik over artiklen og vurdere kvaliteten af de statistiske resultater. Artiklerne er struktureret i afsnittene “Abstract”, “Introduction”, “Methods”, “Results” og “Discussion” (AIMRD), og AIMRD-opbygningen svarer mere eller mindre til trinnene i den videnskabelige proces skitseret i figur 1.
Lidt afhængigt af traditionerne indenfor forskellige fag kan der være byttet lidt rundt på rækkefølgen og afsnittene kan hedde noget lidt andet. Eksempelvis kaldes “Methods” for “Methods and Materials” i nogle tidsskrifter og “Discussion” er nogle steder splittet op i “Discussion” og “Conclusion” — men de følger typisk samme overordnede struktur.
Figur 1: Den videnskabelige proces er dynamisk og dækker: 1) formulering af problemet, der ønskes belyst, 2) planlægning af forsøget og dataindsamlingen, 3) dataindsamling, -organisation og -rensning, 4) statistisk analyse og visualisering og 5) konklusion og opsummering af fund. Resultatet af processen betyder, at vi opdaterer vores viden og opfattelse af problemstillingen, hvilket giver anledning til at processen kan starte igen med afsæt i vores nye viden.
For en mere detaljeret indføring i at læse de statistiske aspekter af videnskabelige artikler kan man se “How to read a paper: Statistics for the non-statistician. I: Different types of data need different statistical tests” og “How to read a paper : getting your bearings (deciding what the paper is about)” af Trish Greenhalgh.
Abstract indeholder et kort resume, og giver en oversigt over artiklens formål, et eller to hovedresultater og en kort konklusion.
Introduction giver baggrunden for den problemstilling og hypotese(r), som artiklen vil belyse. Introduktionen forklarer, hvorfor det videnskabelige arbejde blev iværksat, hvad man allerede ved om emnet, og en opsummering af eksisterende forskning og resultater på området.
Methods fortæller hvordan artiklens hypotese(r) er blevet undersøgt. Hvilke data har været til rådighed, og hvordan er data indsamlet? Hvilke analysemetoder og antagelser har været anvendt til at trække informationer ud af de tilgængelige data, og hvordan er resultaterne og hypoteserne vurderet.
Results viser hvad man har fundet ud fra de tilgængelige data og de anvendte metoder. Resultatafsnittet præsenterer ofte kun de faktuelle analyseresultater uden yderligere kommentarer eller vurderinger.
Discussion sammenfatter og diskuterer hvad resultaterne betyder i forhold til problemstillingen, og hvilke forbehold, man bør have i mente, når resultaterne fortolkes. Der konkluderes, hvad man opnået af ny eller bekræftende viden ud fra studiet, og nogle gange udstikkes ideer til fremtidig forskning.
Her vil vi primært fokusere på de dele af artiklen, der har med de statistiske aspekter at gøre. De relevante detaljer findes som regel i metodeafsnittet og indeholder både oplysninger om data og dataindsamlingen, forsøgsdesignet og om de anvendte statistiske metoder. Det er ikke ualmindeligt, at informationen om analysemetoderne er gemt i et selvstændigt statistikafsnit, der ofte lever en lidt kummerlig tilværelse. Det skyldes delvist tidsskrifternes pladsbegrænsninger, og delvist at det måske ikke er helt klart, hvad der er relevant at inkludere.
Formålet med at præsentere og beskrive de anvendte statistiske metoder er at sikre, at læseren selv er i stand til kan vurdere resultaterne og for at sikre, at studiet er replicerbart. Et studie er replicerbart, hvis det er muligt at gentage forsøget i en anden population eller andet laboratorium og analysere de nye data på samme måde og dermed checke, om man opnår lignende resultater.1 Et replicerbart studie svarer til en grundig brødopskrift: Det er ikke tilstrækkeligt bare at sige: “rør vand, mel, salt og gær sammen og bag brødet”. For at andre kan genskabe det samme brød, skal der være detaljer nok om mængdeforhold, typen af mel og bagetider. Det betyder, at der skal være tilstrækkelig med informationer omkring hvilke variable har man undersøgt og de anvendte modeller. Er der inkluderet og justeret for andre variable modellen og i bekræftende fald hvordan? Er der lavet modelkontrol og hvordan? Hvad har man gjort med manglende værdier? Har man taget højde for multiple tests? Hvilke andre valg har man foretaget undervejs og så videre.
Ideelt set skal informationen i statistikafsnittet sikre, at resultaterne i studiet er reproducerbare. Et studie er reproducerbart, hvis der er tilstrækkelig med information omkring analysen og analysemetoderne til at andre vil være i stand til at genskabe de præcis samme resultater og figurer, hvis de fik det oprindelige datasæt.2 Det ikke kun andre, der skal kunne genskabe analyseresultaterne — det er også en selv. En grundig dokumentation er også nødvendig, når man har brug for at vende tilbage til en af sine tidligere analyser. Specielt set i lyset af, at det ikke er muligt at stille opklarende spørgsmål om den oprindelige analyse til ens “gamle jeg”. Det kan ikke understreges nok, hvor vigtigt det er at gemme og dokumentere alle oplysninger om analysen, og til det formål hjælper R os. Ved at gemme R-scripts for alle analyserne er man i stand til at dokumentere og genskabe nøjagtig de samme resultater, og dermed sikre, at forskningen er reproducerbar.
Der findes mange gode retningslinjer for, hvordan man afrapporterer statistiske metoder og resultater fra eksempelvis kliniske forsøg (CONSORT — Consolidated Standards of Reporting Trials3 Se “CONSORT 2010 Statement: updated guidelines for reporting parallel group randomised trials”) og fra observationelle studier (STROBE — STrengthening the Reporting of OBservational studies in Epidemiology4 Se “The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) statement: guidelines for reporting observational studies”), og disse kan bruges som rettesnor, når informationerne omkring de statistiske analyser skal skrives.
Hvad skal man være opmærksom på, når man læser en artikel?
Når man læser videnskabelige artikler er der en række spørgsmål, der er værd at stille sig selv for at få overblik over studiet og for at undgå fejlfortolkninger. Spørgsmålene er naturligvis kun vejledende og skal hjælpe til at vurdere, om man skal have tiltro til artiklens resultater og konklusioner. Som altid er det vigtigt at være lige kritisk overfor påstande og resultater, som understøtter ens eksisterende forestilling om verden, som de påstande og konklusioner, der peger i en anden retning.
Hvad er forskningshypotesen?
- Har forskningshypotesen været klar og veldefineret fra
begyndelsen? Hvorfor er studiet lavet og artiklen skrevet?
- Er udgangspunktet for studiet en eller flere præspecificerede hypoteser eller har artiklen en mere eksplorativ karakter? Det har betydning for den måde, som resultaterne og konklusionen senere formuleres.
Hvilke data er til rådighed?
- Hvordan er data indsamlet? Følger dataindsamlingen eksempelvis et randomiseret kontrolleret klinisk forsøg, er data observationelle eller har studiedeltagerne meldt sig til studiet?
- Har man indsamlet data, der kan belyse den konkrete problemstillingen, eller har man kun data, der besvarer et andet spørgsmål?
- Har man indsamlet alle de variable, der er relevante for at kunne undersøge hypotesen? Mangler der oplysninger om variable, der kan konfundere (sammenblande) og dermed påvirke de fundne sammenhænge?
- Kan der være selektionsbias? Kan udvælgelsesmekanismen eller analysen have introduceret kunstige sammenhænge i data?
- Hvilken population repræsenterer individerne i stikprøven? Hvilke populationer kan resultaterne generaliseres til?
- Er der overblik over manglende data? Hvad er omfanget af manglende data, og kendes årsagen til at data mangler? Er det for eksempel på grund af censurering, prøveresultater, der er gået tabt eller personer der ikke dukker op til undersøgelser.
Hvordan er data analyseret?
- Hvilken model er benyttet til at analysere data? Kan denne model bruges til at undersøge hypotesen? Er der en sammenhæng mellem det, man gerne vil undersøge i studiet, og det man rent faktisk undersøger?
- Er modellernes antagelser opfyldt?
- Har man justeret for de nødvendige/relevante variable?
- Er der risiko for overfitting så de fundne effekter kan være for optimistiske? Har forfatterne eksempelvis brugt det samme datasæt til først at finde en model og bagefter teste om den virker?
- Hvordan har man håndteret manglende observationer i analyserne?
- Er der nok oplysninger om analysemetoden til at kunne genskabe resultaterne, hvis man fik fat i datasættet?
Hvordan præsenteres resultaterne?
- Passer præsentationen med artiklens formål?
- Svarer præsentationen af resultaterne til den anvendte statistiske model?5 Estimaterne fra en logistisk regressionsmodel er eksempelvis odds ratioer, og skal derfor ikke præsenteres som relative risici. Hvis der præsenteres relative effekter bliver de tilsvarende absolutte niveauer også vist, så den praktiske betydning af resultaterne kan vurderes?
- Bliver der præsenteret både biologiske effektstørrelser og
statistiske vurderinger? Effektstørrelserne og deres usikkerhed bør præsenteres, når
det er muligt, da de beskriver effekterne i den “virkelige verden”.6 Det er ikke tilstrækkeligt kun at vise estimaterne. Til gengæld er det også værd at vurdere, om de estimerede effektstørrelser har værdier, der virker realistiske i den virkelige verden. Virker tallene plausible?
- Svarer beskrivelsen af effektstørrelsen til den anvendte model?
- Hvis flere analyseresultater fremvises kan de så fortolkes på samme måde? Fortolkningen af resultaterne afhænger af, hvilken model, der er brugt til de enkelte analyser, og hvilke andre variable, der indgår i modellen.7 Det kan anbefales at læse “The Table 2 Fallacy: Presenting and Interpreting Confounder and Modifier Coefficients” af Westreich og Greenland.
Hvordan sammenfattes konklusionerne?
- Hvis artiklen kommer med kausale konklusioner om årsagssammenhænge har forfatterne så benyttet statistiske designs og/eller analysemetoder, der retfærdiggør kausale konklusioner? Eller er det sammenhænge/associationer, der er fundet i studiet.
- Hvis forfatterne har undersøgt mange hypoteser har de så valgt kun at præsentere /fokusere på nogle få interessante resultater uden at tage hensyn til alle de andre analyser, der også er foretaget.8 På engelsk kaldes dette fænomen for \(p\)-hacking eller slet og ret “cherry picking”. Hvordan vælger forfatterne i det hele taget at præsentere deres konklusioner, hvis de har undersøgt flere hypoteser eller hvis de startede eksplorativt og uden veldefinerede hypoteser?
- Hvis artiklen tester hypoteser med \(p\)-værdier er forfatterne så opmærksomme på, at en \(p\)-værdi på over 0.05 ikke er ensbetydende med, at der ikke er nogen effekt?
- Kan resultaterne fra studiet generaliseres til andre situationer eller har forsøgsomstændighederne været specielle eller urealistiske? I hvor stor udstrækning kan resultaterne overføres til andre populationer?
Listen over spørgsmål er naturligvis ikke udtømmende, og det er ikke alle spørgsmål, der vil være relevante for alle studier. De dækker imidlertid problemstillinger, der ofte er værd at forfølge og få klarlagt i videnskabelige artikler.