Hvorfor er det svært at forudsige epidemier, lige efter de er gået i udbrud?
Covid-19 har lukket Danmark ned, og vi skal alle vænne os til at holde social afstand og til midlertidig frivillig hjemmekarantæne. Epidemien er utrolig fremtrædende i alles bevisthed, og nye historier, kommentarer, tal, modeller og figurer dominerer dagligt de traditionelle og sociale medier. Er der intensivpladser nok på hospitalerne? Hvor længe vil epidemien vare? Hvor mange vil dø?
Den allestedsnærværende interesse har også medført, at mange personer har kastet sig over at analysere de offentliggjorte tal fra Statens Serum Institut for at se, hvordan epidemien vil udvikle sig. Det er positivt, at problemstillingen har vækket så mange personers interesse for at analysere data, men man skal være ekstra varsom med konklusionerne fra disse analyser, for det er desværre ikke let at forudsige forløbet af et nyt virusudbrud.
Det, der gør det svært at modellere Covid-19 og andre udbrud er, at vi gerne vil forudsige forløbet tidligt, på et tidspunkt, hvor vi ikke har ret mange data, hvor kvaliteten af de tilgængelige data er lav, og hvor vi ikke har nogen måde at validere, om den anvendte model overhovedet passer før udbruddet har løbet til ende. Ingen af delene er fordrende for at opnå særlig præcise forudsigelser.
Hvilke data er der til rådighed?
Data omkring udbruddet kommer fra mange forskellige kilder, og sider som Statens Serum Institut og covid19data.dk stiller data til rådighed så alle kan giv sig i kast med at analysere data.
Hvis vi holder os til de officielle danske data oplyst fra Statens Serum Institut (SSI), så har vi lige nu 4 typer registreringer at gøre godt med: antallet af personer, der er testet for Covid-19, andelen af de testede, der har vist sig at være inficeret, hvor mange, der er hospitaliserede, og hvor mange døde. Af disse kan vi forvente, at de to sidste registreringer er ret nøjagtige - i det mindste så længe vi ikke er løbet tør for intensivpladser på hospitalerne.1 En af de oplysninger, der har været efterspurgt er antallet af personer, der har haft virussen, og som nu er erklæret raske, men disse data har vi ikke til rådighed fra Danmark endnu. De faktiske tal fra SSI omkring indlæggelser og døde kan ses i figur 1 nedenfor fra det tidspunkt, hvor de er blevet indsamlet og offentliggjort. Data er indhentet 26. marts 2020.
Figur 1: Den danske udviklingen i antallet af personer, der er hospitaliseret, på intensiv, i respirator og døde med Covid-19. Hospitaliseringer er først offentliggjort fra SSI fra 17. marts, mens opgørelsen af dødsfald dækker alle dødsfald registreret indenfor 60 dage efter påvist Covid-19 infektion. Covid-19 er ikke nødvendigvis den grundlæggende årsag til dødsfaldet!

De relevante tal for at beskrive epidemiens udvikling er antallet af personer, der er smittet med virussen og hvor mange, der allerede har haft den. Problemet med disse to tal er, at vi kun har bekræftende registreringer for de personer, der rent faktisk er blevet testet positive, mens personer, der er asymptomatiske eller har haft så svage symptomer, så de ikke er undersøgt eller blevet testet ikke indgår i denne statistik.2 Når man hører, at 1300 personer er testet positive så må de 1300 repræsentere en nedre grænse for antallet af inficerede. Der er et mørketal som man kun kan gisne om, og hvad det reelle tal er, er svært at sige. De personer, der er blevet udvalgt til at blive testet er desuden ikke et tilfældigt udsnit af den danske befolkning, men personer, der af den ene eller anden grund har givet anledning til at blive testet: de har for eksempel enten symptomer eller har været i kontakt med personer med Covid-19. Det er derfor en ikke-repræsentativ stikprøve vi har data fra, og når man ikke ved, hvordan den er ikke-repræsentativ, så er den næsten umulig at bruge. En del af modelleringen bliver derfor nødt til at bero på gisninger om, hvordan verden hænger sammen.
Antallet af døde og intensive indlæggelser er kun indirekte mål for, hvordan epidemien udbredes. De vil være ekstra nyttige med tiden, for hvis sandsynligheden for en alvorlig udvikling hos patienterne kan antages at være konstant over epidemien (desværre ikke helt sikkert), så burde udviklingen i antallet af intensivindlæggelser og døde følge mørketallet med en passende forsinkelse. Disse tal - som også er de mest præcise - kan altså hjælpe os senere i epidemiens udvikling, men er mindre nyttige i starten af forløbet.
Det betyder, at der er ret få data til rådighed, og som vi kan tro på tidligt i forløbet, og konsekvensen er, at meget input til modellerne ender med enten at være kvalificeret gætværk, informationer, der “lånes” fra tidligere udbrud af andre sygdomme, eller informationer fra andre lande, der er længere fremme i Covid-19 udbruddet. Hvis vi låner informationer omkring tidligere udbrud af andre sygdomme, så er man nødsaget til at gøre sig nogle antagelser om, at Covid-19 ligner de andre sygdomme, og det ved man først meget senere i forløbet. Hvis vi låner informationer fra andre lande bliver man nødt til at antage, at hospitalsvæsenet, dataregistreringer, den måde man bruger sundhedsvæsenet, og den måde, der testes for virussen er sammenlignelige med det danske system. Med andre ord skal der foretages en række valg før man kan overveje at bruge andre data.
Sammenligning med andre lande
Udbruddene i Kina og Italien startede flere uger før det danske og måske kan udviklingen i disse lande give en indkation af, hvordan det kommer til at forløbe i Danmark.
Befolkningssammensætningen og sundhedsvæsenet i de to lande er ret forskellige og er forskellige fra det danske. Med andre ord kan vi ikke være sikre på, at vi kan overføre data fra de andre lande til Danmark - selv hvis vi havde dem.
Figur 2: Udviklingen i antallet af døde på grund af Covid-19 i udvalgte lande. Landene er først taget med efter 5 dødsfald. Raten af døde lader til at følge nogenlunde samme mønster i starten. Kina skiller sig ud, men de er også flere uger længere fremme i forløbet end resten af verden, og deres registreringer er muligvis ikke så offentlige som i andre lande.

Selvom dødelighederne ser ud til at følge samme mønster, så afspejler dette tal også forskelle i landenes befolkningssammensætning. Befolkningssammensætningen i fx Italien og Danmark er vist i befolkningspyramiderne nedenfor. Italien har en meget ældre population, og hvis Covid-19 rammer hårdere blandt de ældre, så vil den samlede dødelighed vokse kraftigere i landet med den ældre befolkning. For at kunne overføre dødeligheds- eller hospitaliseringsrisikoen fra eksempelvis Italien, kræver det, at man benytter aldersspecifikke rater da befolkningssammensætningen er helt anderledes end i Danmark.
Figur 3: Populationspyramider for Danmark og Italien. Formen viser den relative andel af en befolkning, der er i hver aldersgruppe opdelt efter mænd (røde) og kvinder (sorte). Formen i Danmark og Italien er ret forskellig, og Italien har en meget større andel af befolkningen, der er lige under 60. Hvis dødeligheden for Covid-19 afhænger af alderen så vil den rå dødelighed i de to populationer se helt forskellig ud.

SIR-modellen
En af de klassiske modeller til at beskrive udbredelsen af smitsomme sygdomme er SIR-modellen, som vi tidligere har skrevet om her og her. I dens simpleste form inddeles befolkningen i tre grupper: S (susceptible, dvs andelen, der er modtagelige for sygdommen), I (infected, hvor stor en andel, der har sygdommen i udbrud) og R (recovered, der er andelen, der allerede har haft sygdommen, og derfor ikke kan få den igen), og modellen kan bruges til at beskrive udviklingen af flere smitsomme sygdomme så som mæslinger, influenza, kopper, fåresyge, røde hunde osv.3 I praksis anvendes en mere avanceret version af SIR-modellen eller en netværksmodel, men problemstillingen om, hvad man skal fodre modellen med er den samme.
SIR-modellen har i sin simpleste form 2 parametre: R0 og infektionsperioden. R0 angiver antallet af personer, som en smittebærer i gennemsnit vil smitte i en population, hvor alle andre er modtagelige, og infektionsperioden bestemmer, hvor længe den inficerede kan smitte andre.
Et eksempel er vist i figuren nedenfor, hvor man har brugt, R0=2.5 og en infektionsperiode på 14 dage. Modellen gør sig en masse andre antagelser, blandt andet , og vigtigst af alt tager denne simple model ikke højde for politiske indgreb, ændringer i holdninger i befolkningen, og det faktum, at vores nuværende bud på R0 og infektionsperioden stadig er usikre og fejlbehæftede.
Figur 4: SIR-modellen udregner udviklingen i befolkningens fordeling i de tre grupper: modtagelige (S), inficerede (I), og raske (R). Denne simple model bruger kun oplysninger om R0 og infektionsperioden, og de tre kurver får resultatet til at se meget nøjagtigt ud.

Modellen viser præcist, hvad der vil ske hvis alle antagelser omkring modellen er korrekte og hvis R0 er netop 2.5 og infektionsperioden er præcis 14 dage. Resultatet med de tre kurver i figur 4 signalerer en præcision og nøjagtighed i forudsigelserne, som vi i virkeligheden slet ikke kan stå inde for.
Vis usikkerheden
Når resultaterne fra en statistisk model formidles er det vigtigt samtidig at kommunikere den tilhørende usikkerhed. Det er i sig selv ikke noget problem, hvis resultaterne er usikre, så længe denne usikkerhed også vises, så modtageren selv kan vurdere, hvor stor tiltro man skal have til dem. I den henseende er SIR-modellen og de andre modeller til at beskrive udviklingen af Covid-19 ingen undtagelse.
I eksemplet ovenfor (figur 4) benyttede vi værdier R0=2.5 og 14 dages infektionsperiode, som var disse værdier givne. I praksis kender vi ikke de sande værdier af R0 og infektionsperioden, men vi har måske en ide om, hvad de kunne være. Hvis vi tror, at R0 formentlig er omkring 2.3, men kunne være lidt større eller lidt mindre, og hvis infektionsperioden er et-eller-andet mellem 9 og 16 dage, så tillader vi, at vores usikkerhed omkring de pågældende parametre kan spille ind på slutresultaterne, og det betyder, at usikkerheden omkring data og modellen kan illustreres (se figur 5).
Figur 5: Den simple SIR-model (og de fleste andre modeller) er ret følsom overfor antagelser omkring værdien af R0 og infektionsperioden, og disse usikkerheder afspejles kun alt for sjældent i de resultater, der fremlægges. Hvis vi repræsenterer vores usikkerhed omkring værdien af R0 som vist i den lille figur øverst til venstre, og vores usikkerhed omkring værdien af infektionstiden i den lille figur øverst til højre, så videreføres denne usikkerhed til SIR-modellens resultater. 500 forskellige kombinationer af R0 og infektionsperioden er forsøgt, og de 500 tilhørende kurver viser, hvor meget resultaterne kan ændre sig.
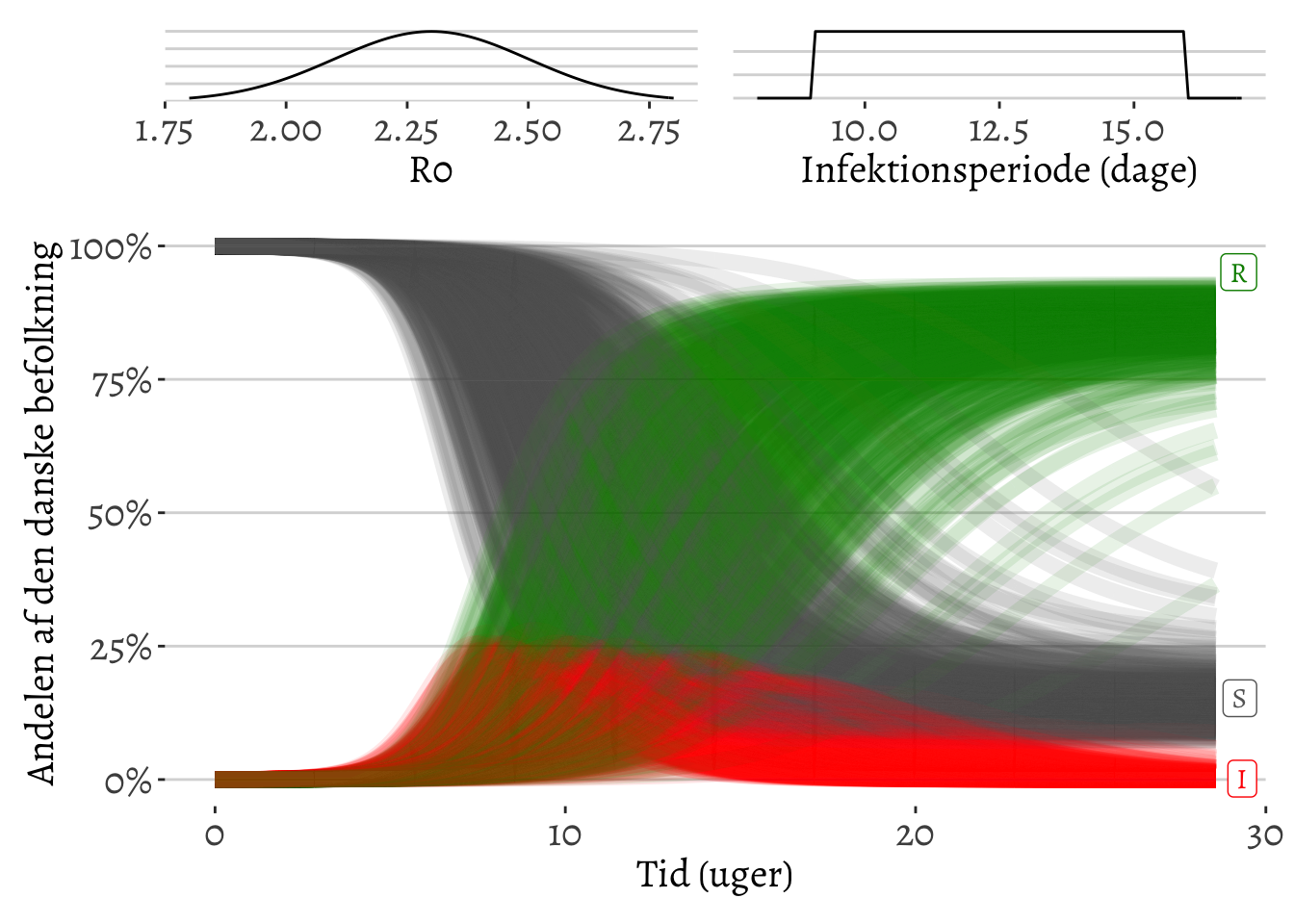
Forskellen på figur 4 og figur 5 er slående. Usikkerheden omkring vores antagelser er helt forsvundet i figur 4 så viser figur 5 til gengæld, at modellen godt nok har nogle grove bud på det overordnede forløb, men at det er svært at sige noget om de finere nuancer. Og det er stadig under forudsætning af, at den anvendte model er den korrekte!
Det kan ikke understreges nok, hvor vigtigt det er, også at formidle usikkerheden omkring resultaterne videre til modtageren.
Betydningen af de politiske tiltag
De politiske tiltag så som at holde afstand, at arbejde hjemmefra, og afholde undervisning online er alle forsøg på at nedbringe antallet af personer, som hver inficerede smitter, R0. Tiltagene er ikke for at reducere den samlede andel af danskere, der får sygdommen, men at sikre, at udviklingen af sygdommen er tilstrækkelig langsom til, at sundhedsvæsenet kan håndtere de personer, der måtte have brug for det.
En gruppe britiske forskere fra Imperial College London har for nyligt udgivet en rapport, der forsøger at beskrive effekten af disse forskellige politiske tiltag på befolkningens dagligdag. Fælles for resultaterne i rapporten er, at de fundne effekter også er behæftet med en usikkerhed, der bør afspejles i efterfølgende afrapporteringen, hvis rapporten benyttes. Derudover benytter forfatterne selv en model med en række antagelser, og hvorvidt disse antagelser omkring tiltagene holder, er stadig uklart.
Hver af disse tiltag betyder imidlertid, at modellens antagelser ikke længere er opfyldte og at man er nødsaget til at gætte, hvordan tiltagene påvirker modellen og hvad effekten af de påståede tiltag er. For hvert politisk tiltag bliver der altså smidt grus i modelleringsmaskineriet, hvilket gør de fundne resultater endnu mere usikre.
Skal vi så helt droppe at modellere udviklingen?
Statistiske modeller bruger data til at beskrive og forudsige det overordnede billede for en konkret problemstilling, og gode statistiske modeller gør os i stand til at agere og have en fornemmelse af, hvad fremtiden vil bringe. En god statistisk analyse laves i tæt samarbejde med fagvidenskaben. Kun gennem input fra personer der forstår problemstillingen og data kan man lave en ordenlig statistisk analyse, der kan tage ordenlig hånd om de vigtigste usikkerheder. Naive anvendelser af modeller som SIR-modellen eller andre kan let føre til alt for “sikre” forudsigelser om epidemiens udvikling.
I disse dage skal vi være ekstra varsomme med ikke at misinformere og skabe frygt og bekymring. Det er også gældende for velmenende, men forkerte dataanalyser. Hvis man ikke ved, hvad data helt præcist repræsenterer, hvis man ikke er sikker på, hvor data stammer fra, eller de begrænsninger og underliggende antagelser, der er omkring de modeller man bruger, så bidrager man til og har et medansvar for de forkerte historier, der misinformerer og forplumrer forsøget på at håndtere epidemien på bedst mulige vis. Så vær forsigtig og ansvarlig!